- Как сделать голос робота – создаем эффект компьютерного голоса для песен и озвучек
- Способ 1. Используем готовый эффект компьютерного голоса
- Шаг 1. Откройте аудиозапись в программе
- Шаг 2. Примените эффект робота к голосу на записи
- Шаг 3. Сохраните измененный трек
- Способ 2. Создание имитации голоса робота вручную
- Голосовой модулятор (звуковые эффекты вибрато и голос робота)
- Голосовой бот + телефония на полном OpenSource. Часть 1 — создание и обучение текстового бота RU
- Шаг 1: Предобработка датасета
- Шаг 2: Преобразование датасета в понятный для NN вид
- Шаг 3: Создание модели
- Шаг 4: Обучение модели
- Шаг 5: Пытаемся поговорить с нашим ботом
- Синтезатор речи «для роботов» с нуля
- Небольшое замечание касательно выбора способа реализации синтеза речи
- Под спойлером представлен результат обработки речи вокодером
- Краткая теория работы вокодера
- Не все так просто
- Что дает такой способ синтеза речи?
- Немного кода
Как сделать голос робота – создаем эффект компьютерного голоса для песен и озвучек
При создании музыки или видео симуляция голоса робота – один из самых популярных звуковых эффектов. Такой прием применяют при создании треков в стиле техно, развлекательных видеороликов с вымышленными персонажами или для озвучки. Из нашей инструкции вы узнаете два легких способа, как сделать голос робота на компьютере полностью с нуля или при помощи готовых эффектов.
Способ 1. Используем готовый эффект компьютерного голоса
Существует несколько вариантов получения нужного результата, в том числе использование редакторов в режиме онлайн. Однако мы в этой статье мы будем разбирать процесс работы на примере программы для записи и обработки голоса на русском языке АудиоМАСТЕР. В отличии от большинства онлайн-площадок, этот софт не зависит от стабильности и мощности соединения и не портит качество звукового файла. Редактор уже включает в себя готовый пресет «автоматизированного», электронного голоса, так что вам останется лишь применить его.
Шаг 1. Откройте аудиозапись в программе
Сначала вам потребуется скачать программу для наложения эффекта робота на голос – АудиоМАСТЕР – и установить ее на компьютер. Сделать это можно, кликнув по кнопке ниже.
Запустите редактор и выберите подходящий способ импорта аудиофайла. Вы можете загрузить готовый трек из памяти компьютера, с телефона, флешки и даже с CD-диска. Также АудиоМАСТЕР предлагает опции, позволяющие вытянуть звуковую дорожку из видеоролика или записать свой голос через подключенный микрофон.
Разнообразные варианты эхо помогут создать нужную атмосферу
Шаг 2. Примените эффект робота к голосу на записи
В колонке с инструментами слева выберите пункт «Изменить голос». Откроется окно с готовыми аудио-фильтрами. Нам подходит пресет «Робот» – он преобразует человеческий голос в роботизированный за счет повышения исходной тональности и добавления звенящего эха.
Чтобы добиться более насыщенного или, наоборот, менее выраженного эффекта, отредактируйте предложенные в появившемся окне дополнительные настройки:
- Темп отвечает за скорость проигрывания дорожки. Продвигая слайдер влево, вы увеличиваете темп аудиодорожки, двигая вправо – уменьшаете. Имейте в виду, что эти настройки также влияют на высоту голоса.
- Громкость эха в данном случае отвечает за «звенящий» эффект в голосе. Вы можете увеличивать интенсивность этой настройки от 0 до 100%.
- Число ревербераций позволяет настраивать имитацию отражения звука в помещении. Максимальное значение – 8.
- Сдвиг высоты тона изменяет голос на более высокий или низкий тембр. Таким образом можно имитировать речь женского или мужского бота.
Примените фильтр с эффектом голоса робота и подстройте его под свой вкус
Все изменения можно предварительно прослушать. Для этого воспользуйтесь соответствующей кнопкой. Когда вы добьетесь нужного звучания, наложите эффект кнопкой «Применить».
Шаг 3. Сохраните измененный трек
Вот и все, что требуется для того, чтобы получить озвучку или песню голосом робота! Чтобы сохранить дорожку, откройте «Файл» в главном меню программы и выберите команду «Сохранить как. ». Этот способ экспорта позволит сохранить исходную аудиодорожку не тронутой! Обработанную запись можно отправить на жесткий диск или флешку в форматах MP3, WAV, WMA, MP2, AAC, AC3, OGG, FLAC. Если вам нужен только конкретный участок песни, выделите его левой кнопкой мыши и выберите вариант «Сохранить выделенное».
Вы можете сохранить обработанный трек полностью или частично
Способ 2. Создание имитации голоса робота вручную
Применение готовых аудиоэффектов – не единственная возможность, которая есть в АудиоМАСТЕРЕ. Если с помощью предыдущего способа вы не смогли добиться желаемого результата, советуем выполнить обработку голосового файла с нуля. Получить оригинальный роботизированный голос можно, задействовав несколько инструментов – эффект эха, тональность, реверберацию и темп.
- Чтобы изменить темп аудиодорожки, воспользуйтесь соответствующим пунктом в списке доступных эффектов в левом столбце. Повышая значение скорости, можно добиться высокого смешного «мультяшного» голоса, а понижая – низкого размеренного звучания, который подходит для страшных роликов. Это отличный вариант, если вы хотите сделать озвучку голосом робота на видео. В окне настроек можно включить опцию плавного изменения темпа – так голос будет постепенно меняться до установленного параметра без резких скачков.
Перемещайте ползунок на шкале, чтобы ускорить или замедлить скорость воспроизведения трека
Примените один из готовых эхо-фильтров или настройте отражение звука вручную
В программе есть специальный режим эффекта реверберации для компьютерного голоса
Показатель степени смещения тональности вы выставляете вручную
Теперь вы знаете, как сделать компьютерный голос буквально за несколько минут. Это хороший способ исказить речь на записи, если вы хотите разыграть друга, а также беспроигрышный эффект для тех, кто озвучивает мультфильм или текст для ролика. АудиоМАСТЕР позволяет производить запись озвучки для видео и обрабатывать заранее подготовленные дорожки, вы сможете применять к аудиофайлам готовые аудиоэффекты в один клик и создавать их с нуля без особых знаний и навыков. Скачать и опробовать приложение можно совершенно бесплатно, благодаря удобному интерфейсу вы сможете освоить аудиомонтаж в короткие сроки.
Источник
Голосовой модулятор (звуковые эффекты вибрато и голос робота)
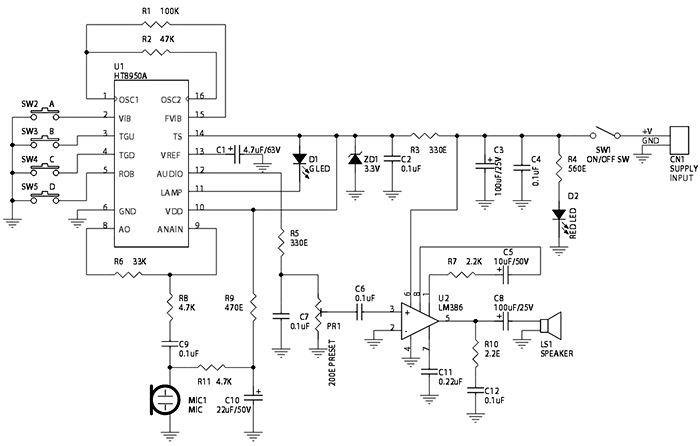
В проекте данного голосового модулятора используется микросхема HT8950A, которая создает два специальных звуковых эффекта, а именно – вибрато и голос робота.

Описание проекта
В данном проекте создается два специальных эффекта: вибрато и голос робота. Эффект вибрато генерируется путем изменения частоты входного сигнала вверх и вниз на частоте 8 Гц. Второй эффект создается путем преобразовании входного голоса в голос робота. Оба эффекта могут быть выбраны в зависимости от того, какой вход срабатывает, ROB или VIB. Для смещения уровня частоты на выходе микросхема имеет семь ступеней, которые выбираются с помощью нажимных кнопок SW0, SW1 и SW2 для прямого выбора электронным способом, которые подключаются к входам микросхемы ROB, TGD, TGU и VIB.
Микросхема HT8950 включает встроенный усилитель со смещением для микрофона, 8-битный АЦП, встроенную память SRAM, а также 8-битный ЦАП токового выхода. 8-битные АЦП и ЦАП обеспечивают частоту дискретизации 8 кГц, гарантируя высокое качество и высокое отношения сигнал/шум выходного голоса. Микросхема управляет светодиодным индикатором, который мигает в соответствии с уровнем входного голоса.
Характеристики:
Входное питание — 6 В DC @ 300 мА
Звуковой выход — Динамик, 8 Ω / 0.5 Вт
7 ступеней для смещения уровня частоты (Регулировка громкости) SW3 (TGU) и SW4 (TGD)
SW2 – Режим вибрато, SW5 – Режим робота
Светодиод для отображения уровня входного голоса
Ползунковый переключатель ВКЛ/ВЫКЛ для подачи питания
Аудио усилитель LM386 с предустановками уровня громкости
PBT (клеммная колодка источника питания) коннекторы для подачи напряжения питания и подключения выходного динамика
Светодиодный индикатор подачи питания
Размер печатной платы 63 мм x 68 мм
CN1 – Вход источника питания 6 В DC
MIC1 – Электретный конденсаторный микрофон
LS1 – Динамик
Электрическая схема
Печатная плата (с видом снизу)
Источник
Голосовой бот + телефония на полном OpenSource. Часть 1 — создание и обучение текстового бота RU

В наше время голосовые роботы набирают огромную популярность, от банального заказа такси, до продаж клиентам. Создание голосового бота сводится к трем базовым этапам.
- Распознавание голоса ASR.
- Выяснение смысла сказанного и поиск необходимых сущностей в тексте(к примеру адрес, сумма, ФИО итд )
- Генерация ответа, преобразование текста в речь TTS. Мы пройдем от пути создания простого текстового бота до интеграции с системой телефонии freeswitch с распознаванием голоса и озвучиванием подготовленных ответов. Данная статья описывает используемые инструменты и путь по их интеграции вместе для создания голосового робота.
В первой части поговорим о создании простого текстового бота, которого можно встроить в чат.
Пример разговора Б-бот Ч-человек
Бот работает на принципе понятия намерения пользователя. На каждое намерение есть список заготовленных ответов. Чтобы бот мог понять намерение пользователя, необходимо обучить модель на датасете с намерениями и фразами, которые могут активировать это намерение
Намерение: Поздороваться
Возможные фразы: привет, добрый день, дратути…
Ответ: Привет
Намерение: Попрощаться
Возможные фразы: Пока, До свидания, Прощай…
Ответ: Пока
Шаг 1: Предобработка датасета
За основу взят датасет из открытого обучения skillbox по написанию чат бота в телеграмм, который может пообщаться с вами на тему кино. Выложить не могу по понятным причинам.
Предобработка является очень важным этапом.
Первым делом уберем все символы и цифры из текста и приведем все к нижнему регистру.
Далее необходимо исправить опечатки и ошибки в словах.
Эта задача не самая простая, есть хороший инструмент от Yandex под названием Speller, но он ограничен по числу запросов в день, поэтому будем искать бесплатные альтернативы
Для python есть замечательная библиотека jamspell, которая неплохо исправляет опечатки. Для нее есть хорошая предобученная модель для русского языка. Прогоним все входные данные через эту библиотеку. Для голосового бота этот шаг не так актуален, так как система распознавания речи не должна выдавать слова с ошибками, она может выдать не то слово. Для чат бота этот процесс необходим. Так же для минимизации влияния опечаток можно обучать сеть не на словах, а на n-граммах.
N-граммы, это части слов, состоящие из n букв. к примеру 3-граммы для слова привет будут
при, рив, иве, вет. Это поможет быть менее зависимым от опечаток и повысит точность распознавания.
Далее необходимо привести слова к нормальной форме, так называемый процесс лемматицизии слов.
Для данной задачи хорошо подходит библиотека rulemma .
Так же можно из фраз убрать стоп слова, которые несут мало смысловой нагрузки, но увеличивают размер нейронной сети (я брал из библиотеки nltk stopwords.words(«russian»)), но в нашем случае лучше их не убирать, так как пользователь может ответить роботу только одним словом, а оно может быть из списка стоп слов.
Шаг 2: Преобразование датасета в понятный для NN вид
Для начала необходимо сформировать словарь из всех слов датасета.
Для обучения модели понадобится перевести все слова в oneHotVector
Это массив, которые равен длине словаря слов, в котором все значения равны 0 и только одно равно 1 в позиции слова в словаре.
Далее все входные фразы преобразовываются в 3-х мерный массив, который содержит все фразы, фраза содержит список слов в формате oneHotVector — это и будет наш входной датасет X_train.
Каждой входной фразе нужно сопоставить подходящее к ней намерение так же в формате oneHotVector — это наш выход y_train.
Шаг 3: Создание модели
Для небольшого бота достаточно маленькой модели с двумя слоями lstm и двумя полносвязными слоями:
Компилируем модель и подбираем оптимизитор, я выбрал adam, так как он давал лучший результат.
Шаг 4: Обучение модели
После подготовки датасета и компиляции модели можно запустить ее обучение. Так как датасет небольшой, пришлось обучать модель на 250-500 эпохах, после чего происходило переобучение.
Шаг 5: Пытаемся поговорить с нашим ботом
Чтобы поговорить с нашим ботом, надо на вход обученной модели подать правильно подготовленные данные. Пользовательский ввод необходимо обработать так же как и датасет из первого шага. Дальше преобразовать его в вид, понятный NN как во втором шаге используя тот же словарь слов и их индексы, чтобы входные слова соответствовали словам, на которых проводилось обучение.
Обработанный ввод подаем в модель и получаем массив значений, в котором присутствуют вероятности попадания нашей фразы в то или иное намерение, нам же необходимо выбрать то намерение, у которого самая высокая вероятность, это можно сделать через библиотеку numpy
Необходимо оценить уверенность сети в этом ответе и подобрать порог, при котором выдавать пользователю failure phrases, типа — я вас не понял. Для своих целей я установил порог в 50% уверенности, ниже которого бот скажет, что не понял вас.
Далее из списка наших намерений выбираем подходящий ответ и выдаем его пользователю
Источник
Синтезатор речи «для роботов» с нуля
Давным-давно посетила меня идея создать синтезатор речи с «голосом робота», как, например, в песне Die Roboter группы Kraftwerk. Поиски информации по «голосу робота» привели к историческому факту, что подобное звучание синтетической речи характерно для вокодеров, которые используются для сжатия речи (2400 — 9600 бит/c). Голос человека, синтезированный вокодером, отдает металлическим звучанием и становится похожим на тот самый «голос робота». Музыкантам понравился данный эффект искажения речи, и они стали активно его использовать в своем творчестве.
Поиски информации по реализации вокодера вывели меня на книгу «Теория и применение цифровой обработки сигналов», где расписано почти все, что необходимо для создания собственного синтезатора речи на основе вокодера.
Небольшое замечание касательно выбора способа реализации синтеза речи
Конечно, можно было бы и не париться с созданием вокодера, а просто сделать базу заранее записанных звуков всех фонем и проигрывать их в соответствии с текстом. Данный способ мне не был интересен, поэтому я решил сделать синтезатор речи именно с синтезом всех звуков, как согласных, так и гласных. Вокодер для этих целей был выбран потому, что его проще обучить, чем формантный синтезатор речи, хотя звучание в обоих случаях было бы именно то, которое мне нужно. К тому же, синтезирование звуков, возможно, позволит реализовать синтезатор речи на базе микроконтроллера stm32 без внешней памяти! Вопрос тут скорее в том, хватит ли скорости работы МК.
Под спойлером представлен результат обработки речи вокодером
Краткая теория работы вокодера
Самая основная часть вокодера — это гребенка полосовых фильтров. Именно она формирует спектр синтетической речи или, наоборот, определяет уровни спектра естественной человеческой речи в приемной части устройства. Как передающая, так и принимающая часть вокодера содержит гребенку полосовых фильтров.
Принимающая человеческую речь часть вокодера также определяет, помимо спектра звука, является ли звук шумовым, или у него есть тон. Для тона определяется его период. Сигналы с выходов полосовых фильтров детектируются, пропускаются через ФНЧ и используются в дальнейшем в качестве коэффициентов для модуляции сигналов на полосовых фильтрах синтезирующей части вокодера.
Синтезирующая часть вокодера содержит генератор шума и тона (читай: генератор случайной числовой последовательности на основе сдвигового регистра и генератора меандра), а также переключатель между этими двумя генераторами. Сигнал от одного из двух генераторов подается на вход гребенки полосовых фильтров. Для каждого фильтра на входе сигнал от генератора тона или шума модулируется соответствующим коэффициентом. И наконец, с выхода всех фильтров суммируем сигнал и получаем синтезированную речь.
Если кто не понял мое описание работы вокодера, вот блок-схема:
Не все так просто
Чтобы вокодер хоть как-то понятно звучал, нужно выполнить пару требований к его полосовым фильтрам. Нет времени объяснять, просто поверье, что нужно использовать БИХ фильтры Бесселя (пруфы на 749 странице). Также, нужно распределить спектр речи неравномерно по фильтрам, особенно если у нас их немного (в моей реализации вокодера их всего 16 штук). Есть еще одна прелюбопытнейшая вещь, с которой вы можете ознакомиться все в той же книжке. А именно, представим, что сначала мы пропускаем сигнал от генератора тона или шума через гребенку фильтров, затем с выхода каждого фильтра ограничиваем сигнал двумя уровнями -1 и +1 и затем модулируем сигналы и снова пропускаем каждый сигнал через такой же фильтр, как ранее. По идее, такая схема не должна давать ощутимой разницы в синтезируемой речи. Тем не менее, такой прием выравнивания спектра существенно улучшает синтетическую речь вокодера. Почему так, лучше прочесть в книжке. Ну а тем, кому лень читать, скажу кратко: это из-за флуктуаций речи человека. На картинке снизу представлена блок-схема «улучшения» вокодера.
Что же касательно того, как распределить частоты между фильтрами… Основные частоты человеческой речи находятся в диапазоне примерно до 4-5 кГц (очень примерно). Я взял предел в 4 кГц и, используя психофизическую единицу измерения высоты звука «мел», распределил равномерно, правда не по герцам, а по мелам.
Что дает такой способ синтеза речи?
Если коэффициенты модуляции полосовых фильтров «смещать» по номеру фильтра, можно получить из женского голоса мужской. И это несмотря на то, что диапазоны фильтров (в моей реализации вокодера) в частотной области распределены не равномерно.
Также можно менять интонацию речи, можно вообще все менять. Единственный минус остается отстойное низкое качество речи.
Прослушать то, как меняется женская речь в мужскую, можно тут:
Немного кода
Весь код я пока выкладывать не буду (так как еще не дописал синтезатор речи — будет вторая статья). Ниже представлен код для определения высоты основного тона (также можно определить, тон или шум). Для этого измеряется энтропия сигнала, энтропия сигнала после ФНЧ на 600 Гц (в частотной области тона), а также число правильных совпадений в определителе периода тона.
Источник