- ИнтервьюКак сделать словарь русского языка, который захочется читать
- Новый школьный энциклопедический словарь русского языка, созданный коллективом СПбГУ, отличается от других в первую очередь оформлением. Градиенты, выборка фотографий и статьи, будто бы почёрканные маркером старательного школьника — дело рук дизайнера Ждана Филиппова. Но оформление тесно связано с концепцией словаря, который создатели предлагают читать «как книгу». Даниил Трабун поговорил с Сергеем Монаховым и Дмитрием Чердаковым о том, зачем нужно издавать словарь на бумаге в эпоху гипертекста и как сделать учебную литературу нескучной.
- Как так вышло, что с одной стороны, это официальный словарь русского языка, одобренный всеми инстанциями, а с другой стороны, — он, скажем так, дерзкий? Свежий и свободный в каком-то смысле.
- Можно поподробнее про книгу для чтения? Всё-таки к словарю обращаются, только когда он действительно нужен.
- Об оформлении
- В глаза сразу бросается оформление. Каким образом коллектив, который занимался подбором статей и структурой словаря, работал с дизайнерами? Как я понимаю, это должна быть довольно плотная совместная работа?
- О вопросах в словаре
- Если зайти сегодня в книжный магазин, кажется, что не так чтобы очень много оригинальных учебников выходит.
- Об образовательной литературе, которую потребляют современные школьники, если как-то сужать.
- HackWare.ru
- Этичный хакинг и тестирование на проникновение, информационная безопасность
- Продвинутые техники создания словарей
- Оглавление
- Азы генерации словарей
- Атака на основе правил
- Генерация словарей на основе информации о человеке
- Составление списков слов и списков имён пользователей на основе содержимого веб-сайта
- Как создать словарь по маске с переменной длиной
- Удлиняющиеся пароли в Hashcat
- Удлиняющиеся пароли в maskprocessor
- Когда о пароле ничего не известно (все символы)
- Создание словарей, в которых обязательно используется определённые символы или строки
- Как создавать комбинированные словари
- Как комбинировать более двух словарей
- Как создать все возможные комбинации для короткого списка строк
- Комбинирование по алгоритму PRINCE
- Гибридная атака — объединение комбинаторной атаки и атаки по маске
- Как создать комбинированный словарь, содержащий имя пользователя и пароль, разделённые символом
- Как извлечь имена пользователей и пароли из комбинированного словаря в обычные словари
- Как при помощи Hashcat можно сгенерировать словарь хешей MD5 всех шестизначных чисел от 000000 до 999999
- Удвоение слов
- Как создать словарь со списком дат
- Заключение
- Связанные статьи:
- Рекомендуется Вам:
- 5 комментариев to Продвинутые техники создания словарей
ИнтервьюКак сделать словарь русского языка, который захочется читать
Преподаватели СПбГУ совместно с дизайнером Жданом Филипповым выпустили школьный словарь в дерзком оформлении

Текст
 Новый школьный энциклопедический словарь русского языка, созданный коллективом СПбГУ, отличается от других в первую очередь оформлением. Градиенты, выборка фотографий и статьи, будто бы почёрканные маркером старательного школьника — дело рук дизайнера Ждана Филиппова. Но оформление тесно связано с концепцией словаря, который создатели предлагают читать «как книгу». Даниил Трабун поговорил с Сергеем Монаховым и Дмитрием Чердаковым о том, зачем нужно издавать словарь на бумаге в эпоху гипертекста и как сделать учебную литературу нескучной.
Новый школьный энциклопедический словарь русского языка, созданный коллективом СПбГУ, отличается от других в первую очередь оформлением. Градиенты, выборка фотографий и статьи, будто бы почёрканные маркером старательного школьника — дело рук дизайнера Ждана Филиппова. Но оформление тесно связано с концепцией словаря, который создатели предлагают читать «как книгу». Даниил Трабун поговорил с Сергеем Монаховым и Дмитрием Чердаковым о том, зачем нужно издавать словарь на бумаге в эпоху гипертекста и как сделать учебную литературу нескучной.
 Новый школьный энциклопедический словарь русского языка, созданный коллективом СПбГУ, отличается от других в первую очередь оформлением. Градиенты, выборка фотографий и статьи, будто бы почёрканные маркером старательного школьника — дело рук дизайнера Ждана Филиппова. Но оформление тесно связано с концепцией словаря, который создатели предлагают читать «как книгу». Даниил Трабун поговорил с Сергеем Монаховым и Дмитрием Чердаковым о том, зачем нужно издавать словарь на бумаге в эпоху гипертекста и как сделать учебную литературу нескучной.
Новый школьный энциклопедический словарь русского языка, созданный коллективом СПбГУ, отличается от других в первую очередь оформлением. Градиенты, выборка фотографий и статьи, будто бы почёрканные маркером старательного школьника — дело рук дизайнера Ждана Филиппова. Но оформление тесно связано с концепцией словаря, который создатели предлагают читать «как книгу». Даниил Трабун поговорил с Сергеем Монаховым и Дмитрием Чердаковым о том, зачем нужно издавать словарь на бумаге в эпоху гипертекста и как сделать учебную литературу нескучной. 

Доцент кафедры истории русской литературы филологического факультета СПбГУ

Старший преподаватель кафедры русского языка филологического факультета СПбГУ
Как так вышло, что с одной стороны, это официальный словарь русского языка, одобренный всеми инстанциями, а с другой стороны, — он, скажем так, дерзкий? Свежий и свободный в каком-то смысле.
Дмитрий: Идея создать такой словарь родилась в Санкт-Петербургском государственном университете ещё в 2009 году. Главный вопрос здесь — зачем вообще делать новый словарь, если уже есть другие, так ведь? Всё верно, существуют энциклопедические справочники, в том числе предназначенные для школьников, ориентированные на школьный курс русского языка. Но нам этой справочной функции самой по себе было недостаточно. Мы хотели, чтобы помимо выполнения этой важной роли, словарь стал своего рода учебником и даже книгой для чтения. Был не просто источником получения информации, но и способствовал пониманию читателями тех сведений, которые в нём сообщаются. Эта идея совмещения функций воплощалась разными средствами — как на уровне текста, так и собственно в дизайнерском решении.
Можно поподробнее про книгу для чтения? Всё-таки к словарю обращаются, только когда он действительно нужен.
Сергей: Да-да, это такая распространённая идея. Словарь стоит на полке, к полке подходят, открывают книгу, смотрят нужное слово, ставят обратно. Мы хотели сделать иначе. Образно говоря, не словарь на полке в ряду других книг, а словарь — открытый — на столе, книга для каждой семьи. Наш словарь состоит из двух частей. Первая — это собственно корпус энциклопедических статей. Второй корпус — указатели, которые помогают читателю сориентироваться в этом информационном пространстве. Помимо традиционных алфавитного и терминологического указателей, в словаре присутствует древовидный тематический указатель, в котором статьи расположены иерархически с разными уровнями вложенности по степени обобщения терминологического материала. Поймите правильно, никто не предполагает, что человек откроет словарь и начнёт фигачить с буквы А и до конца, пока не дочитает. Но он может, обратившись к нашему терминологическому древу, сформировать представление о том лингвистическом контексте, который существует вокруг интересующего его явления, прочитать целый кластер статей, связанных друг с другом.
Есть ещё один момент, который делает словарь «книгой для чтения». Помимо основного текста, в статьях у нас даются вставные очерки двух типов — какие-то более или менее обширные цитаты из художественной или научной литературы, иллюстрирующие то понятие, которое в статье раскрывается, а с другой стороны, дополнительные, научно-популярные, небольшие тексты, которые позволяют – опять-таки, да? – читателю интересующее его явление представить в более широком контексте.
Об оформлении
ЖДАН ФИЛИППОВ, дизайнер словаря: «Хотелось, чтобы по образу [в словаре] дружило несколько штук. Чтобы это был WordArt — настоящий, ужасный, но уточнённый. Чтобы от него оставалась только тонкая тень присутствия. Плюс Лазарь Лисицкий и градиент с куртки 80-х годов. В общем, это как будто презентация в Word или Excel, но она чуть-чуть более точная, в общем. Это весело выглядит — как словарь, но ещё и весело. Весёлый словарь. В каких-то моментах это выглядит криво, косо, но всё совершенно осознанно и ровно так, как должно быть в данном случае. Бодро, дерзко, но формально мы выполнили все правила. Мне кажется, так и нужно»
Ждан Филиппов рассказывает о том, как создавалось оформление словаря
В глаза сразу бросается оформление. Каким образом коллектив, который занимался подбором статей и структурой словаря, работал с дизайнерами? Как я понимаю, это должна быть довольно плотная совместная работа?
Сергей: Работа по дизайнерскому оформлению началась тогда, когда текст был готов. Первоначально, ещё на этапе создания статей, были подобраны иллюстрации, но Ждан Филиппов большинство этих картинок забраковал, сказал, что они никуда не годятся — ни по качеству своему, ни по своему, так сказать, концептуальному встраиванию, что это просто какой-то винегрет, солянка и так далее. Ждан предложил необычное решение — иллюстративный ряд делать чёрно-белым, а сам текст цветным. Раскрашивать текст, выделяя в нём разные информационные потоки: цитаты, ссылки, списки, понятия, вставные очерки, имена писателей и названия произведений. Понятно, что в куче книг, словарей, энциклопедий есть такие «подвалы» с цветовой заливкой, но это совсем другое. Там цвет маргинален и маркирует маргинальные, периферийные вещи. А у нас это основный эстетический приём. Когда Ждан предложил эту идею, я помню этот момент — как озарение, божественное озарение.
Параллельно с работой над словарем мы работали и над макетом учебника по русскому языку для 10–11 классов. В том, что касается школьников, это одного возрастного уровня адресат. Макет учебника делал Дима Барбанель, с которым, как и со Жданом, мы познакомились, когда работали над журналом «Эрмитаж», и вот с тех пор время от времени сотрудничаем. Я к чему — к тому, что эти два макета, учебника и словаря, — в них можно при желании усмотреть две противоположности. В том смысле, что Дима как раз забабахал в учебник огромное количество совершенно разностильных, в том числе просто ужасных, иллюстраций; вынес их в такие резервации, на отдельные развороты, отженил от текста и дал им возможность взрывать глаз и мозг читателя. А Ждан жёстко всё выкинул. Не было бы счастья, да несчастье помогло — стало понятно, что у нас нет картинок, и пришла идея, которая мне до сих пор нравится, — создание такой вот особой текстовой выразительности.


О вопросах в словаре
Дмитрий: «Почему в русском языке шесть падежей? Возьмём, к примеру, «говорил о лесе, гулял в лесу», и там и тут — предложный падеж. Почему вдруг предложный падеж — хотя разные окончания, разные вопросы, разные предлоги, и вообще нет ничего общего? Стоит задуматься. И такого рода проблемных вопросов — вопросов, которые, говоря высоким языком, будят мысль, побуждают человека чем-то заинтересоваться, а не довольствоваться самой скупой информацией, — в словаре немало»
Если зайти сегодня в книжный магазин, кажется, что не так чтобы очень много оригинальных учебников выходит.
Дмитрий: Вы сейчас говорите именно об учебниках?
Об образовательной литературе, которую потребляют современные школьники, если как-то сужать.
Дмитрий: Могу говорить только о русском языке. Учебники по русскому языку и структурированы, и в дизайнерском отношении оформлены традиционно. Безусловно, это скучно, и мы, конечно, хотели от этой скуки немного отойти, но тут очень важны пропорции и меры. Надо помнить, что учение — не развлечение, как бы этого ни хотелось, и в традиционности, может быть даже какой-то косности, есть свои плюсы. По этим «скучным» учебникам все мы выучились, в русской учебно-методической традиции накоплен богатейший опыт, богатейший арсенал приёмов обучения русскому языку. Возможно, в каком-то смысле этот опыт нуждается в некотором новом преподнесении, — да, и вот мы попытались это сделать.
Сергей: По другим дисциплинам сейчас издают вполне красочные, яркие учебники, но там есть, так сказать, предметная основа для каких-то привлекательных визуальных решений, с русским языком — по понятным причинам — намного сложнее.
Дмитрий: Это не кино и не мультфильм, и как бы ни было сильно влияние визуальной составляющей в современной культуре, не стоит забывать, что в начале было Слово и основа всего — это текст. Беда современной культуры как раз таки в том, что всё распалось на кусочки, понимаете? Всё разлетелось на куски, и настаивать на этом распадении целого, ещё более, так сказать, его акцентировать, преподносить как нечто такое занимательное, на мой взгляд, не нужно. Важно здесь немножечко притормозить.

Учебник русского языка для 10–11 классов, разработанный «Мастерской»: Димой Барбанелем, Сергеем Федоровым, Ильей Коробовым, 42 художниками, 11 фотографами. Для учебника были разработаны 2 шрифта на основе Romanovsky, а также переделан Humanist
Источник
HackWare.ru
Этичный хакинг и тестирование на проникновение, информационная безопасность
Продвинутые техники создания словарей
Оглавление
В этой статье собраны возможные ситуации генерации словарей, с которыми можно столкнуться на практике, но которые ещё не описаны в других статьях. Некоторые примеры взяты из вопросов в комментариях или на форуме, с некоторыми задачами я сталкивался сам.
Будут рассмотрены не только уже знакомые нам инструменты, но и парочка новых. Для некоторых задач мы будем использовать не только специализированные инструменты — некоторые действия проще сделать с помощью стандартных утилит Linux или собственных скриптов.
Поскольку здесь не будут описываться основы генерации словарей, то начнём с перечня источников, где вы можете прочитать эти самые основы. Рекомендуется прочитать их, если вы ещё не сделали этого.
Азы генерации словарей
Атака на основе правил
Атака на основе правил — изменяет уже существующий словарь по указанному набору правил. Если с помощью атаки на основе правил вы хотите изменить поведение маски, то вначале нужно создать словарь по маске, а затем работать с ним.
Самый простой способ — использовать программу с графическим интерфейсом Mentalist, инструкция: Генерация и модификация словарей по заданным правилам.

Атака на основе правил в John the Ripper намного мощнее чем в hashcat, для данной атаки из этих двух программ рекомендую выбирать именно John: Полное руководство по John the Ripper. Ч.5: атака на основе правил
Генерация словарей на основе информации о человеке
Если пароль составлен на основе данных пользователя, например, комбинация имени, фамилии, даты рождения, именах детей, номера телефона, этих же данных ближайших родственников, то такой пароль можно считать слабым. Рассмотренные выше инструменты не очень подходят для составления подобных словарей, основанных на информации о пользователе — разве что, комбинаторная атака в Hashcat, но она за раз принимает только 2 словаря.
Именно эту проблему решает утилита CUPP.
Установка CUPP в Kali Linux
Установка CUPP в BlackArch
Запустите программу в интерактивном режиме и введите известные данные пользователя:

Пример сгенерированных паролей:
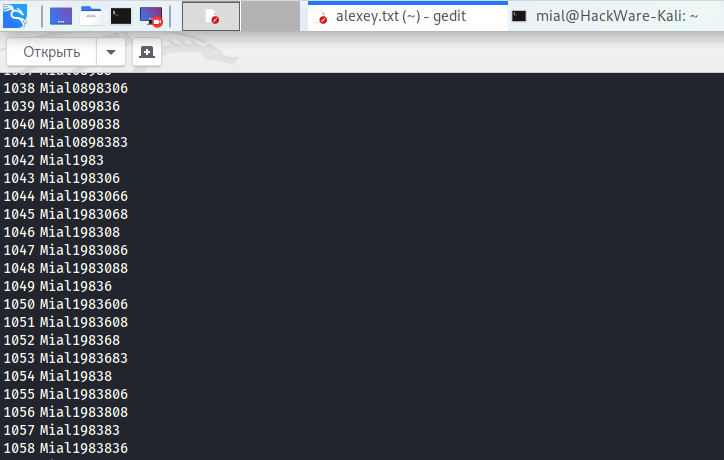
Если вам нужен перевод задаваемых вопросов, то вы найдёте его на странице карточки программы.
Составление списков слов и списков имён пользователей на основе содержимого веб-сайта
Познакомимся с ещё одним инструментом — CeWL. Эта программа обходит указанный сайт (можно указать глубину обхода) и все найденные на страницах сайта слова сортирует в порядке частоты их использования. Зачем нужен такой словарь? Автор предлагает использовать его для брут-форса. К тому же, программа умеет искать e-mail адреса, а также извлекать имена создателей офисных документов — поддерживаются файлы Word и PDF. Эти данные можно использовать для составления списка имён пользователей.
Ещё в комплекте с программой идёт утилита FAB, которая извлекает из уже скаченных документов Word и PDF имена авторов — их тоже можно использовать в качестве имён пользователей для брут-форса.
Установка CeWL в Kali Linux
Программа предустановлена в Kali Linux.
В минимальных версиях программа устанавливается следующим образом:
Установка в BlackArch
В карточке программы описаны дополнительные нюансы установки — рекомендуется ознакомиться.
Примеры запуска CeWL
Запуск сбора слов со страниц сайта https://site.ru, используя только страницы, ссылки на которые будут найдены на указанном адресе (-d 1), для составления словаря, который будет сохранён в файл dic.txt (-w dic.txt):
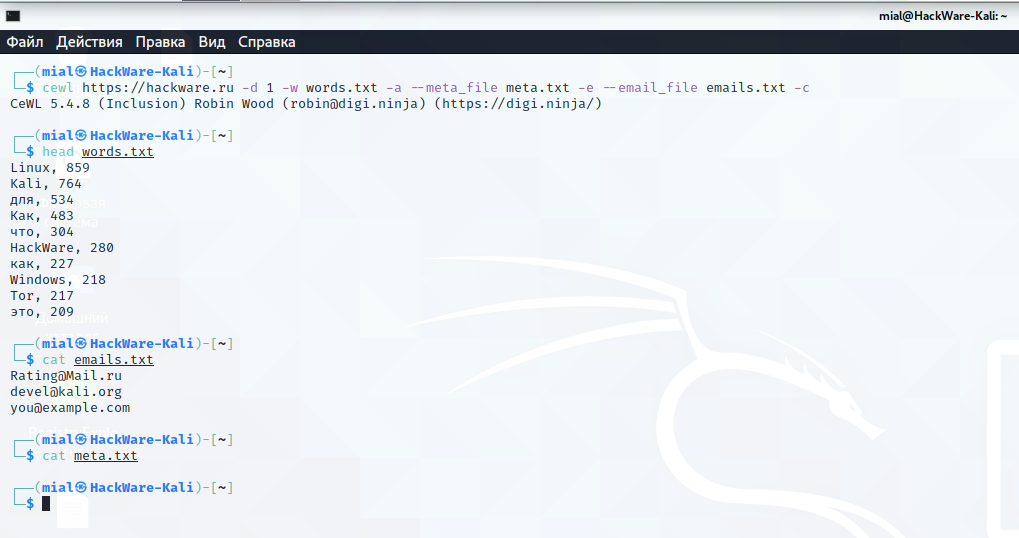
Запуск сбора слов со страниц сайта https://site.ru, используя страницы, ссылки на которые будут найдены на указанном адресе, а также на скаченных страницах (-d 2), для составления словаря, который будет сохранён в указанный файл (-w dic.txt), при этом для каждого слова будет показана частота, с которой он встречается (-c), также будет составлен список найденных email адресов (-e), которые будут сохраняться в указанный файл (—email_file emails.txt) и будет создан список на основе информации найденной в метатегах документов (-a), этот список будет сохранён в указанный файл (—meta_file meta.txt):
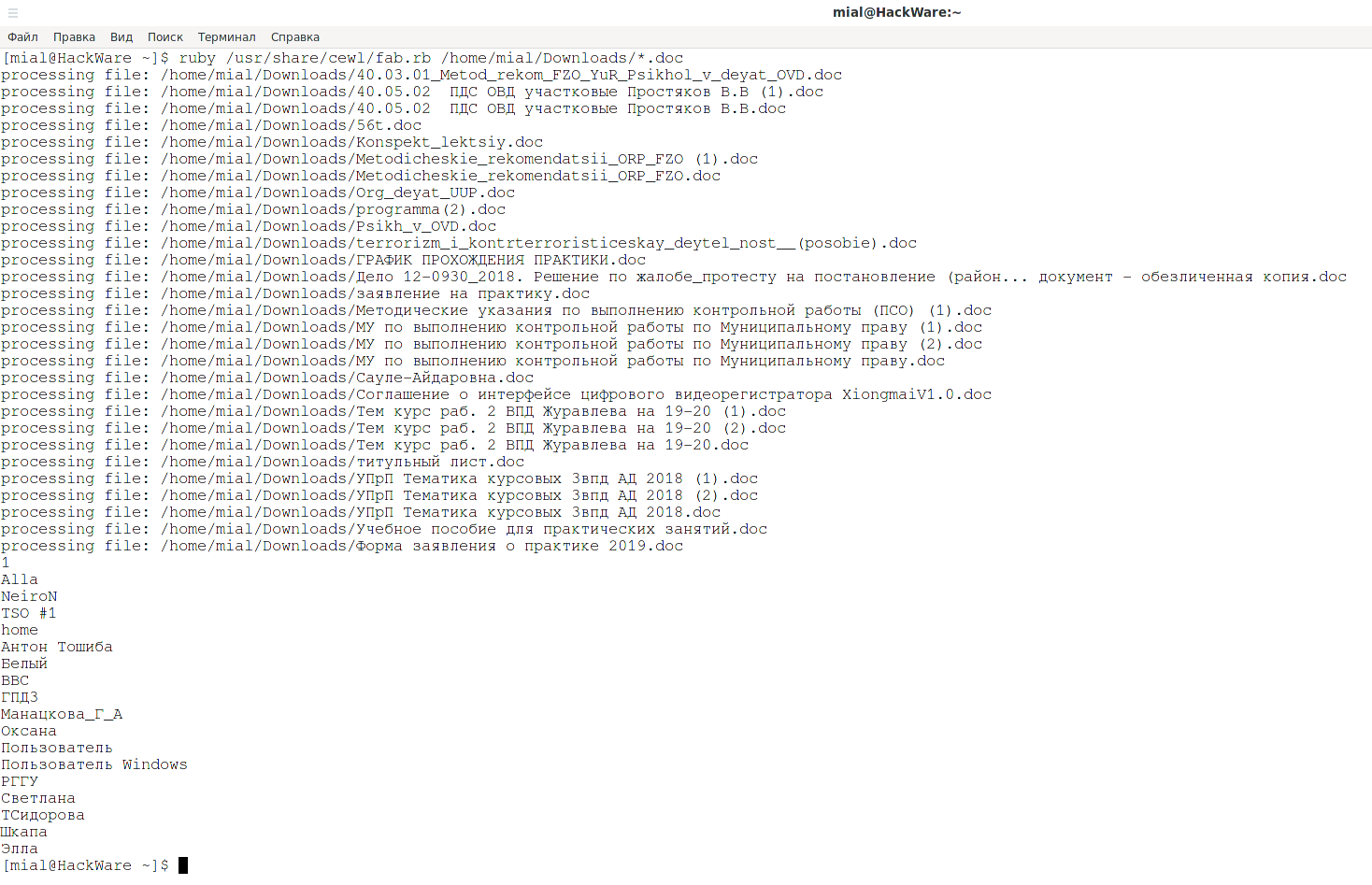
Запуск FAB, при котором будут проверены все документы *.doc в директории /home/mial/Downloads/, из метаинформации этих документов будет извлечено поле, содержащее имя автора документа, данные будут выведены на экран:
Как создать словарь по маске с переменной длиной
Рассмотрим генерацию списков слов различной длины на примере Hashcat и maskprocessor.
Удлиняющиеся пароли в Hashcat
Для того, чтобы генерировались пароли различной длины, имеются следующие опции:
Опция -i является необязательной. Если она используется, то это означает, что длина кандидатов в пароли не должна быть фиксированной, она должна увеличиваться по количеству символов.
Опция —increment-min также является необязательной. Она определяет минимальную длину кандидатов в пароли. Если используется опция -i, то значением —increment-min по умолчанию является 1.
И опция —increment-max является необязательной. Она определяет максимальную длину кандидатов в пароли. Если указана опция -i, но пропущена опция —increment-max, то её значением по умолчанию является длина маски.
Правила использования опций приращения маски:
- перед использованием —increment-min и —increment-max необходимо указать опцию -i
- значение опции —increment-min может быть меньшим или равным значению опции —increment-max, но не может превышать его
- длина маски может быть большей по числу символов или равной числу символов, установленной опцией —increment-max, НО длина маски не может быть меньше длины символов, установленной —increment-max.
Итак, команда запуска для генерации паролей, которые имеют длину от шести до десяти символов:
hashcat -a 3 -i —increment-min=6 —increment-max=10 —stdout ?l?l?l?l?l?l?l?l?l?l
Удлиняющиеся пароли в maskprocessor
В maskprocessor имеется следующая опция приращения:
Следующая команда составит словарь из чисел от 1 до 9999:
Когда о пароле ничего не известно (все символы)
Про нюансы я уже писал, здесь только примеры команд.
Если нужно запустить полный перебор, когда в пароле могут быть большие и маленькие латинские буквы, а также цифры и длина пароля от 1 до 12, то нужно использовать следующие опции и маску:
Чтобы вывести все кандидаты в пароли или сохранить их в словарь:
Если нужно запустить полный перебор, когда в пароле могут быть большие и маленькие латинские буквы, цифры, а также символы !»#$%&'()*+,-./:; ?@[\]^_`
и длина пароля от 1 до 12, то нужно использовать следующие опции и маску:
Чтобы вывести все кандидаты в пароли или сохранить их в словарь:
Создание словарей, в которых обязательно используется определённые символы или строки
В комментариях к статьям о генерации паролей по маскам иногда спрашивают, а как создать словарь, содержащий определённые символы или слова, причём они могут быть в любом месте. На самом деле, именно маски для этого подходят плохо. Задачу можно решить с помощью Атаки на основе правил, особенно если речь идёт об отдельных символах или группах символов — выше уже даны ссылки на решение подобных случаев. Но если речь идёт о строках, то Атака на основе правил становится или слишком сложной и запутанной из-за необходимости создавать большое количество правил, или даже просто невозможной.
Рассмотрим несколько примеров.
Предположим, известно, что в пароле, состоящим из любых символов (большие и маленькие буквы, а также цифры), обязательно присутствует слово «Alexey», которое может быть в любом месте пароля и в любом регистре. Для решения этой задачи вместо того, чтобы создавать безумное количество правил, можно создать словарь со всеми вариантами и просто отфильтровать слова, в которых есть искомая строка, например:
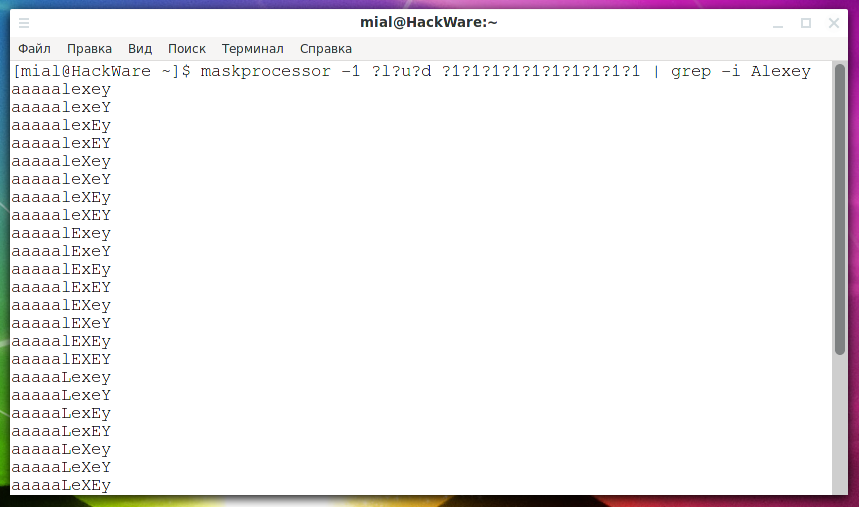
На мой взгляд, это оптимальное решение. Оно также подходит, если вы не хотите создавать словарь, а хотите использовать атаку по маске — многие программы для брут-форса способны принимать кандидаты в пароли из стандартного ввода.
Ещё один вариант — искомое слово может быть в любом регистре, но точно расположено в начале пароля:
Кстати, последний пример не особенно удачный — поскольку нам известно, что вначале возможны только 2 символа — „A“ или „a“, то лучше использовать пользовательский набор символов, включающих эти два символа. Аналогично и для других — хотя бы четырёх известных символов (по количеству возможных пользовательских наборов).
Как создать словарь, обязательно содержащий символы «e», «g», «D» и «t»? Для этого используйте команду вида:
В ней вы можете добавлять цепочку из grep и отфильтровывать пароли с любым количеством необходимых символов.
Как создать словарь, в котором пароли в любом месте и в любом регистре содержат слово «Alexey» или слово «MiAl»? Используйте команду вида:
Количество искомых строк может быть любым:
Пример команды, создающий словарь, в котором кандидаты в пароли состоят только из цифр, но в пароле обязательно должна быть последовательность «12345» расположенная в любом месте:
Думаю, идея понятно — вместо того, чтобы пытаться создать невозможную маску, создаём всё возможное и отфильтровываем то, что нам нужно.
Как создавать комбинированные словари
Комбинированными словарями обычно называют словари, включающие одновременно имя пользователя и пароль, разделённые определённым символом (обычно двоеточие или символ табуляции). Но в данном случае я имею в виду словари, которые составлены из слов разных словарей, путём объединения. Но и к «нормальным» комбинированным словарям мы ещё вернёмся.
Это называется комбинаторной атакой, её подробное описание: https://hackware.ru/?p=283#combinator_attack
Суть в том, что к каждому слову из первого словаря, добавляется каждое слово из второго словаря.
Словарь 1 (dict1.txt)
Словарь 2 (dict2.txt)
Запуск комбинаторной атаки (-a 1):
Мне почему-то казалось, что слова должны объединятся ещё и в обратном порядке (то есть первым идёт слово из второго словаря), но как вы можете убедиться, это не происходит. Поэтому для получения описанного эффекта, нужно запустить атаку ещё раз, поменяв словари местами:
Как комбинировать более двух словарей
Далее показан пример комбинации трёх словарей — суть в том, что каждое новое полученное слово состоит по одному слову из каждого из трёх словарей:
Как комбинировать подобным образом 4 и более словарей? Мне трудно представить, что это может пригодиться в реальной ситуации, но для этого скорее всего придётся писать свой скрипт для автоматизации показанного выше алгоритма. Если вы знаете программы, которые умеют это делать, то пишите в комментариях.
И… в этом месте я вспомнил о программе combinator3. Она поставляется в пакете hashcat-utils. Эта команда служит для комбинации трёх словарей (для комбинации двух словарей используйте combinator).
Эта программа умеет комбинировать по 3 указанных словаря, но опять же — если словарь идёт третьим, то слова из него всегда будут в конце.
Чтобы получить все возможные комбинации из трёх слов в любом порядке, то нужно использовать следующие команды:
Как создать все возможные комбинации для короткого списка строк
Утилита combipow создаёт все “уникальные комбинации” из короткого списка ввода. Эта программа также включена в hashcat-utils.
Пример содержимого словаря с именем wordlist:
Запуск combipow с этим словарём:
Даст следующие результаты:
Комбинирование по алгоритму PRINCE
Программа princeprocessor реализует алгоритм PRINCE. Подробнее об этом алгоритме вы можете узнать на странице карточки программы. Там же описана суть работы программы и её опции.
Примеры использования princeprocessor.
Чтобы создать все возможные цепи из содержимого файла dict1.txt:
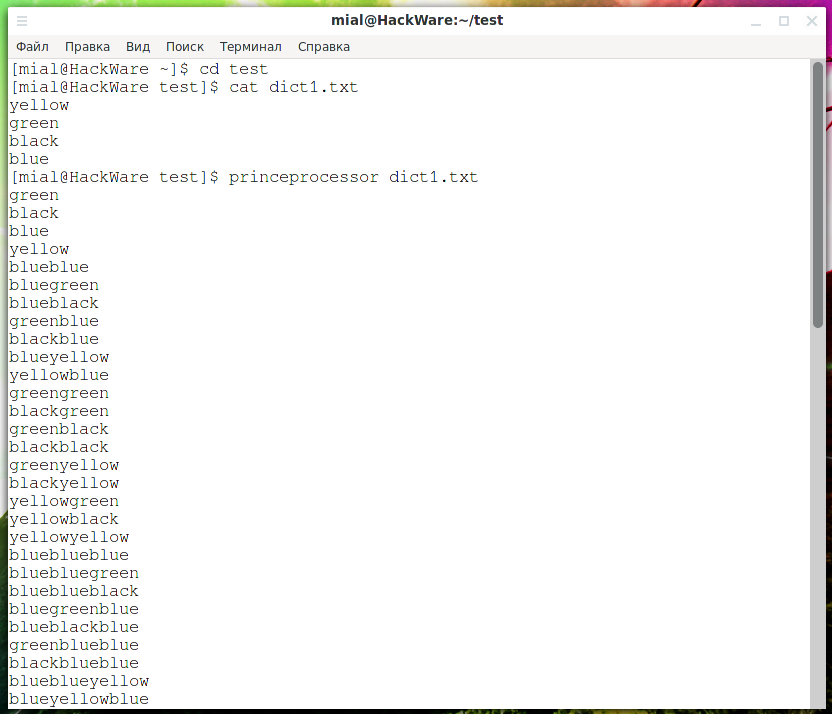
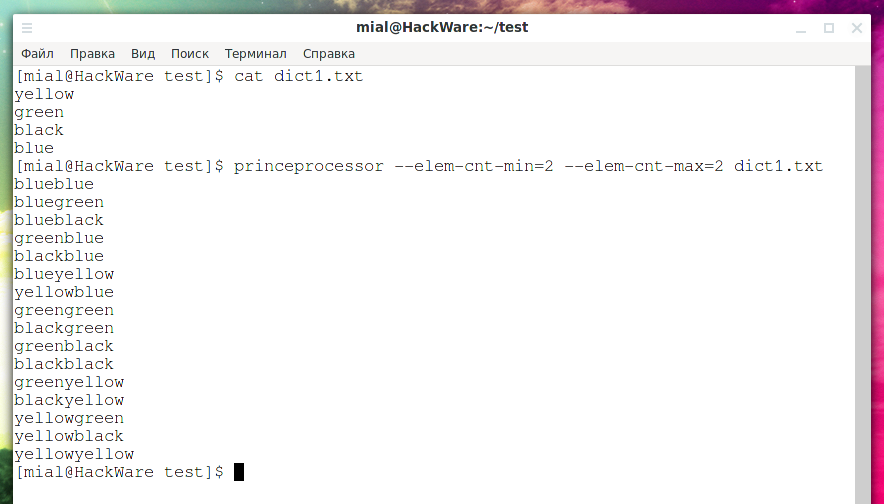
Используя слова из указанного словаря (dict1.txt) составить цепи минимальной длиной 2 элемента (—elem-cnt-min=2) и максимальной длиной 2 элемента (—elem-cnt-max=2), то есть в каждой цепи будет только по 2 слова:
Гибридная атака — объединение комбинаторной атаки и атаки по маске
Эта атака совмещает атаку по словарю и атаку по маске — она принимает на входе словарь и маску и выдаёт гибридный пароль.
Если ваш example.dict содержит:
генерируют следующие кандидаты в пароли:
Это работает и в противоположную сторону!
генерируют следующие кандидаты в пароли:
Все возможности гибридной атаки можно реализовать с помощью Атаки на основе правил — поэтому если она вам нравится больше, то используйте её.
Как создать комбинированный словарь, содержащий имя пользователя и пароль, разделённые символом
Теперь возвращаемся к комбинированным словарям, содержащим одновременно имя пользователя и пароль.
В качестве примера посмотрите на фрагмент словаря (файл auth_basic.txt) программы Router Scan by Stas’M — в нём учётные данные разделены символом табуляции:
А это пример комбинированного словаря, в котором имя пользователя и пароль разделены двоеточием:
Чтобы создать комбинированный словарь, используйте команду вида:
- users.txt и passwords.txt — словари, из которых будут взяты имена пользователей и пароли и будут составлены все возможные комбинации.
- РАЗДЕЛИТЕЛЬ — символ, которым будут разделены логин и пароль
Например, в следующей команде разделителем является двоеточие:

Кстати, если в качестве разделителя нужно вставить символ табуляции, то нажмите Ctrl-v + Tab:
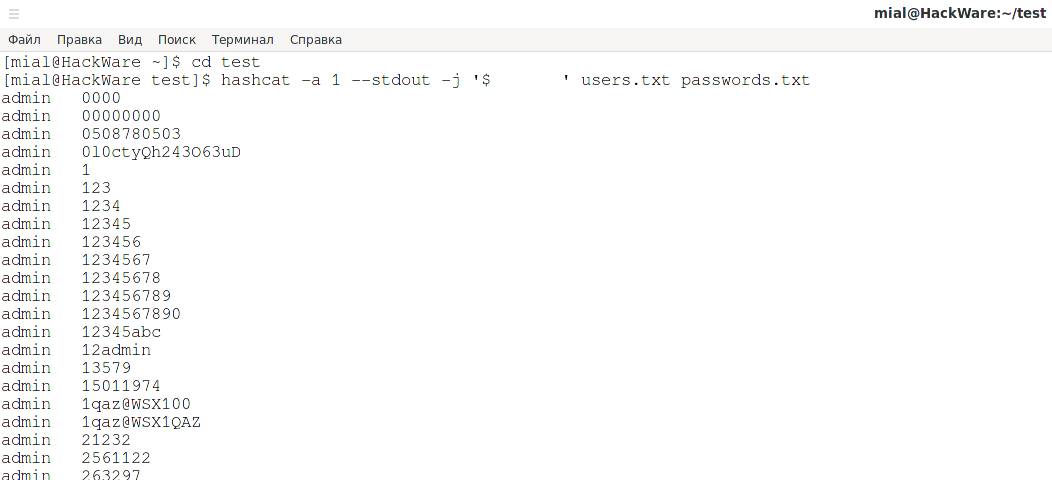
Кстати, если вы попытаетесь разобраться в приведённой выше команде hashcat, то выясните, что одновременно используется Комбинаторная атака и добавлено правило из Атаки на основе правил.
Рассмотрим частный случай: как создать файл парный словарь логинов и паролем такого типа: логин всегда постоянный, затем табуляция и пароль.
Конечно, в качестве первого словаря можно создать файл с одним текстовым полем — логином. Но есть и другой вариант с помощью мощнейшей команды sed:
- superadmin — строка, которую нужно вставить перед каждым паролем
- \t — символ табуляции, который будет разделять логин и пароль
- pass.txt — файл, откуда считывать пароли
- login_pass.txt — новый файл, куда будут сохранены пароли
Если не хотите создавать новый файл, а хотите изменить имеющийся, то уберите перенаправление и добавьте опцию -i:
Как извлечь имена пользователей и пароли из комбинированного словаря в обычные словари
Если из комбинированного словаря нам нужно извлечь только имена пользователей и/или только пароли. Для этого мы воспользуемся (тоже мощнейшей) программой awk.
Смотрите также: Уроки по Awk
Для извлечения имён пользователей:
Для извлечения паролей:
В этих командах:
- РАЗДЕЛИТЕЛЬ — это символ, который разделяет логины и пароли. Если вам нужно указать там символ табуляции, то запишите «\t».
- СЛОВАРЬ.txt — комбинированный словарь из которого мы извлекаем списки слов
В принципе, команды только различаются в $1 (первое поле до разделителя) и $2 (второе поле после разделителя).
Как при помощи Hashcat можно сгенерировать словарь хешей MD5 всех шестизначных чисел от 000000 до 999999
Hashcat может делать радужные таблицы, но только для Wi-Fi.
Зато с помощью PHP эту задачу можно решить несколько строк:
Время выполнение — 1-4 секунды. За это время будут сгенерированы все md5 хеши для строк 000000…999999.
Сохраните приведённый выше код в файл md5-rb-gen.php, запускать так:
Чтобы сохранить полученные хеши в файл:
Интересное наблюдение о скорости достижения задачи.
Следующие две команды делают ровно то же самое:
Но на среднем компьютере выполнение команд займёт до часа. PHP оказался быстрее, чем нативные Linux команды…
Удвоение слов
Как создать словарь 12 символьных слов, состоящих только из десятичных цифр (?d) формата abcdefabcdef, т.е шестизначное число написано два раза?
Можно использовать Атаку на основе правил, а можно написать небольшой скрипт Bash (все слова в из файла user.txt пишутся по 2 раза):
Применительно к нашему заданию — удвоение шестизначных чисел, можно использовать следующую команду, которая сгенерирует числа из шести цифр и дважды запишет каждое число:
Как создать словарь со списком дат
Как создать список дат по шаблону ДД-ММ-ГГГГ, то есть соответствущий маске ?d?d-?d?d-?d?d?d?d но чтобы перебор был не в диапазоне 00-99, а 01-31, 01-12 и 1900-2021 соответственно?
Такие словари умеет создавать программа pydictor.
Но ещё проще словарь сделать следующим образом (он будет сохранён в файл dates.txt):
Если хотите обойтись без создания словаря, то передавайте вывод предыдущие команды на стандартный ввод hashcat:
Заключение
Если я что-то пропустил или есть утилиты, которые делают показанные вещи проще или делают возможным то, о чём я написал что это невозможно, то пишите в комментариях — будет интересно узнать об этом и дополнить статью.
Также можете задавать ваши вопросы, связанные с генерацией словарей, учитывающих определённые условия.
Связанные статьи:
- Генерация словарей по любым параметрам с pydictor (76.9%)
- Генерация и модификация словарей по заданным правилам (63.2%)
- Виды атак Hashcat (62.8%)
- Как создать словари, соответствующие определённым политикам надёжности паролей (с помощью Атаки на основе правил) (60.4%)
- Как использовать радужные таблицы для взлома паролей Wi-Fi в Hashcat и John the Ripper (59.6%)
- Массовый поиск геотэгов на сайтах и в локальном хранилище (RANDOM — 1.5%)

Рекомендуется Вам:
5 комментариев to Продвинутые техники создания словарей
Потрясающая статья, спасибо огромнейшее учитель.
если не затруднит, обьясните пожалуйста эту команду echo <01..31>.<01..12>. <1900..2021>| tr » » «\n» > dates.txt а именно вот это не понятно tr » » «\n»
Если коротко, то выводятся все строки в диапазоне для цифр/букв в фигурных скобках. Если фигурных скобок несколько, то выводятся их общие сочетания.
Чтобы понять, для чего нужно «tr » » «\n»», запустите команду без этой части:
Все сочетания будут выведены, но они будут записаны в одну строку и разделены пробелом. Команда tr, в данном случае, меняет все символы пробела на символ новой строки, который обозначается как «\n».
Источник