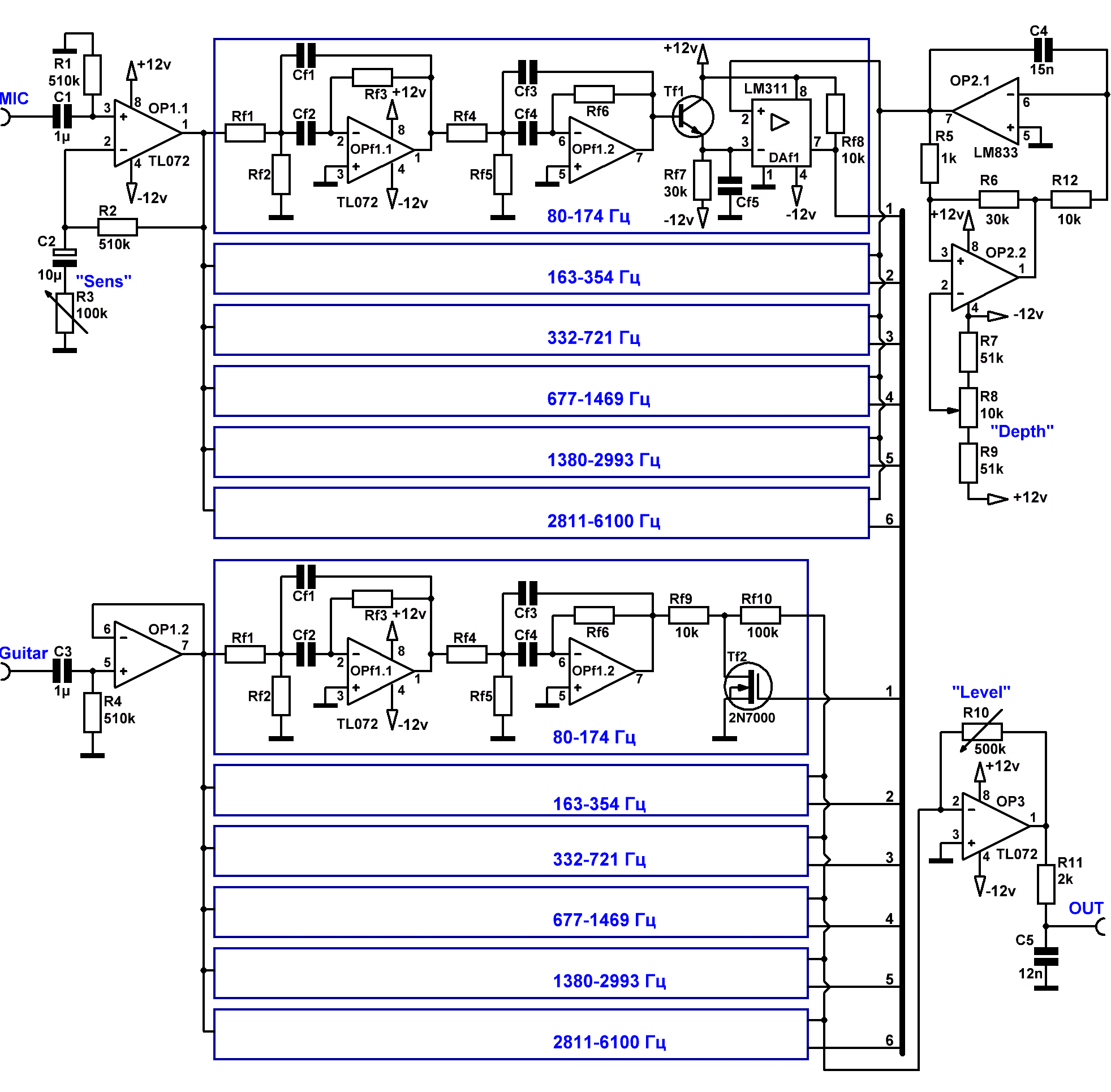
Схема простого вокодера для электромузыкальных инструментов.
Эффект поющей гитары без гастроскопии и прочих неприятных излишеств.
Вокодер — нечастый гость в музыкантской оружейни. Большинство гитаристов, так вообще, обходит эту приблуду стороной, не видя в ней целесообразности для использования в музыке своего жанра. И только отдельные патлатые мужички, местами вполне адекватной наружности, засовывают в рот что-то вроде садового шланга, как будто рассчитывая изжевать его решительно и без остатка. Делая отчаянное лицо: то вытягивая губы вперёд в форме рупора, то широко раскрывая рот, как будто желая что-то исторгнуть из себя, они тем самым реализуют весьма редкий, но интересный эффект “поющей электрогитары”, т.е. звучания инструмента с речевыми особенностями и интонациями голоса человека. Эффект этот называется Talkbox, реализуется достаточно просто, но создаёт неудобства организму исполнителя в виде неприятных ощущений от наличия в полости хавальника постороннего объекта.
Гораздо более гуманными методами можно получить подобный результат при помощи устройства, которое называется вокодер. Вокодер — это полностью электронное устройство, позволяющее перенести свойства сигнала-модулятора, в качестве которого используется голос человека, снимаемый с микрофона, на сигнал, формируемый синтезатором, электрогитарой или иным музыкальным инструментом. А поупражнявшись в освоении своих внутренних голосовых резервов, от вокодера можно ожидать практически неограниченных и недоступных другим примочкам возможностей по обогащению звучания музыкального инструмента выразительными вариантами тембральных и амплитудных эффектов.
Схемотехническим разнообразием данный звуковой эффект не блещет. Пожалуй, единственная схема в русскоязычном исполнении была опубликована в далёком 1984 году в журнале Радио №9. Схема полностью повторила японский Okita Analog Vocoder, с той лишь разницей, что была переведена на отечественную элементную базу. Ни лучше, ни хуже она от этого не стала, при этом «относительная простота» устройства, продекларированная в источнике, вызывает если уж не явное возмущение, то справедливый скепсис — наверняка. Попробуем устранить данный недостаток.
Описываемое устройство относится к полосным (канальным) вокодерам. Полосный вокодер (по типу многополосного графического эквалайзера) разделяет сигнал музыкального инструмента на определённое количество полос (обычно 6-20 полос). Большее число каналов в вокодере даёт большую натуральность и разборчивость. На такое же количество полос разбивается и модулирующий сигнал, поступающий с микрофона. На выходе каждого из микрофонных ПФ включены детектор и сглаживающий НЧ-фильтр, выделяющий огибающую речевого сигнала. Далее всё просто — относительно медленная огибающая речевого сигнала управляет амплитудой находящегося в той же частной полосе инструментального сигнала, после чего выходные амплитуды всех инструментальных каналов суммируются и через регулятор громкости подаются на выход устройства.
Матрица фильтров вокодера покрывает частотную полосу 80-6100 Гц. Эта полоса вмещает в себя как полный частотный диапазон (включая обертоны) электрогитары, так и частотный спектр голоса, несущий максимум информации, связанной с формантной разборчивостью речи.
Поскольку задачи достижения максимально достоверного звучания классического хора мальчиков в рамках данной конструкции не подразумевалось, то было решено ограничиться октавными полосовыми фильтрами (по 6 шт. на весь диапазон), а для усиления глубины звучания вокодерного эффекта применить полосовые фильтры не 2-го порядка (что было бы логично для октавных фильтров), а чего уж там мелочиться, сразу 4-го.
Речевой сигнал усиливается операционным усилителем с нормированной характеристикой шума ОР1.1 и поступает на матрицу фильтров, выполненных на ОУ OPf1.1 и OPf1.2. На выходе каждого из микрофонных ПФ включён пиковый детектор уровня звукового сигнала на транзисторе Tf1 и сглаживающий фильтр R17, Cf5, выделяющий огибающую речевого сигнала. Частота среза данных НЧ-фильтров обычно выбирается ≈1/10 от величины минимальной частоты пропускания полосового фильтра. Далее сигнал, следующий с выхода пикового детектора, управляет коэффициентом передачи аналогичного фильтра, входящего в матрицу фильтров инструментального сигнала. Как это происходит?
А происходит это благодаря жизнедеятельности доморощенного ШИМ-контроллера.
ОР2.1 и ОР2.2 с обвесом — это классический генератор треугольного напряжения. Размах амплитуды выходного треугольного напряжения составляет в теории: Upp ≈ 2Uпит×R5/R6, частота F≈R6/(4R5×R12×C4). В реальной жизни, в связи с проявлением инерционности ОУ, получились значения: Upp≈1В, F≈33кГц. Переменный резистор R8 призван регулировать уровень постоянного смещения треугольного сигнала, а заодно — и глубину влияния модулирующего канала на изменение уровней инструментального.
Треугольное 30-ти килогерцовое напряжение с выхода генератора поступает на прямой (неинвертирующий) вход компаратора, где сравнивается с выходным напряжением детектора огибающей речевого сигнала, подаваемого на инвертирующий вход. Таким образом на выходе компаратора образуется импульсный сигнал с частотой 33кГц и длительностью, зависящей от уровня напряжения на детекторе. Чем больше этот уровень — тем меньше длительность. Далее этот широтно-модулированный сигнал поступает на затвор ключевого транзистора Tf2, который и осуществляет ШИМ регулировку уровня сигнала, поступающего с выхода инструментального фильтра. Чем меньше длительность импульсов (т.е. чем больше уровень напряжения на детекторе) тем слабее влияние, ключевого транзистора на работу делителя, образованного R19 и Rси открытого транзистора, а, соответственно — тем выше амплитуда инструментального сигнала. И наоборот.
Каскад на операционном усилителе ОР3 осуществляет функцию суммирования всех сигналов, поступающих с инструментальных каналов. Потенциометром R10 устанавливается уровень выходного сигнала.
Теперь, что касается элементной базы. Входной усилитель речевого сигнала (ОР1.1) желательно выбрать малошумящим. Операционники, работающие в генераторе треугольного напряжения (ОР2.1, ОР2.2) должны иметь граничную частоту не менее 10МГц. Время задержки переключения компараторов (DAf) — не более 100нс. Транзисторы Tf — любые маломощные, например: КТ3102. К ОУ, работающему в составе фильтров, никаких особых требований не предъявляется.
И напоследок приведу номиналы пассивных элементов полосовых фильтров.
Диапазон (Гц)
Rf1 = Rf4 (кОм)
Rf2 = Rf5 (кОм)
Rf3= R f6 (кОм)
Cf1-4 (нФ)
Сf5 (нФ)
80 — 174
27
8,2
56
68
680
163 — 354
27
8,2
56
33
330
332 — 721
27
10
56
15
150
677 — 1469
22
10
47
8,2
82
1380 — 2993
27
10
56
3,6
47
2811 — 6100
27
10
56
1,8
22
Приведённые в таблице элементы должны иметь отклонения от номинальных значений — не выше 5%.
При исправных деталях и отсутствии ошибок в монтаже устройство не требует налаживания и начинает пахать сразу после включения питания.
Подключив электрогитару (клавишные, балалайку, арфу, либо любой другой предмет, снабжённый звукоснимателем) к инструментальному входу вокодера, покрутите переменный резистор R8, наблюдая за изменением уровня проникновения прямого сигнала инструмента на выход от нулевого до 100%. Чем выше будет установлен этот начальный уровень, тем ниже будет глубина эффекта. Для начала, найдите точку, когда громкость звучания инструмента уже не ненулевая, но достаточно низкая по сравнению с максимальной. А вот теперь можно подключить микрофон к одноимённому входу примочки и голосом музинструмента отправить вокодерного скептика в эротическое путешествие в места заповедные, да и не столь отдалённые.
Источник
Вокодер для голоса своими руками
Прежде всего — С НОВЫМ ГОДОМ!
Срочно нужно выбрать тему для дипломной работы.
В связи с этим хотел бы обратиться к вам. Узнать ваше мнение.
1. Схема для изменения голоса. Суть: Все вы знаете МАКСИМА ГАЛКИНА. Он пародирует знаминитостей. В принципе у каждого человека есть свой тембр голоса, некая постоянная частота его говора. Что если эту постоянную частоту распознать и заменять её на другую, какую вы захотите. Электронно естестно. Вы берёте микрофон — выбираете чим голосом будете говорить и говорите в микрофон своим голосом а спец схема преобразовывает вашу тональность в другую.
Ваше мнение, заранее спасибо.
Последний раз редактировалось Радиогубитель! Сб дек 30, 2006 21:45:53, всего редактировалось 1 раз.
Реклама
Мышонок
Друг Кота
Карма: 6 Рейтинг сообщений: 30 Зарегистрирован: Чт сен 14, 2006 11:42:09 Сообщений: 3792 Откуда: Обитаю на чердаке Рейтинг сообщения: 0
_________________ Память очень интересная штука: бывает так, что запомнишь одно, а вспомнишь другое.
Последний раз редактировалось Мышонок Вс дек 31, 2006 06:15:30, всего редактировалось 1 раз.
Реклама
JLCPCB, всего $2 за прототип печатной платы! Цвет — любой!
Зарегистрируйтесь и получите два купона по 5$ каждый:https://jlcpcb.com/cwc
Цель в принципе проста — создать устройство. Этап 1 : Вы создаёте базу данных в устройстве — где храниться информация о тональностях. Этап 2 : Вы говорите в микрофон. Устройство распознаёт вашу тональность и записывает её в память Этап 3 : Вы выбираете из базы данных устройства нужный голос. Этап 4 : Вы говорите в микрофон а ваша тональность заменяется на выбранную из базы.
Просто у меня знакомая работает на корпоративных вечеринках ей это нужно для пародирования, ну и думаю пригодиться тем кто озвучивает собственные фильмы, чтоб не приглашать много актёров.
Реклама
Сборка печатных плат от $30 + БЕСПЛАТНАЯ доставка по всему миру + трафарет
Не будет ощущаться расхождений в шевелении губ и звука?
Понимаю что зависит от частоты. Но может знаете откуда начинается диапазон тональности у человека. Думаю не с 20 Гц
Реклама
Вебинар поможет в выборе недорогих источников питания оптимальных для систем охраны, промышленных и телекоммуникационных приложений, а также для широкого применения. Будут представлены основные группы источников питания по конструктивным признакам и по областям применения в контексте их стоимости или их особенностей, позволяющих снизить затраты на электропитание конечного устройства.
Приглашаем всех желающих 13 октября 2021 г. посетить вебинар, посвященный искусственному интеллекту, машинному обучению и решениям для их реализации от Microchip. Современные среды для глубинного обучения нейронных сетей позволяют без детального изучения предмета развернуть искусственную нейронную сеть (ANN) не только на производительных микропроцессорах и ПЛИС, но и на 32-битных микроконтроллерах. А благодаря широкому портфолио Microchip, включающему в себя диапазон компонентов от микроконтроллеров и датчиков до ПЛИС, средств скоростной передачи и хранения информации, возможно решить весь спектр задач, возникающий при обучении, верификации и развёртывании модели ANN.
Мышонок
Друг Кота
Карма: 6 Рейтинг сообщений: 30 Зарегистрирован: Чт сен 14, 2006 11:42:09 Сообщений: 3792 Откуда: Обитаю на чердаке Рейтинг сообщения: 0
_________________ Память очень интересная штука: бывает так, что запомнишь одно, а вспомнишь другое.
Карма: 6 Рейтинг сообщений: 30 Зарегистрирован: Чт сен 14, 2006 11:42:09 Сообщений: 3792 Откуда: Обитаю на чердаке Рейтинг сообщения: 0
Ещё надо не забывать про обертоны: НЧ огибающая (иногда даже инфразвуковой частоты).
Есть очень простой способ «металлизации» голоса (это приставки «Дистошн») — обычный усилитель, загоняющий синусоиду в ограничение, т.е. трапецию или даже прямоугольник. Появляется куча высших гармоник и голос приобретает «металлический» оттенок.
Другой способ «Буратино» (по технологии известного фильма). Записываем на одной скорости, проигрываем на другой. Т.е. весь сигнал одинаково смещаем в область высоких частот (проигрывание на большей скорости) или в область НЧ (воспроизведение на меньшей скорости).
_________________ Память очень интересная штука: бывает так, что запомнишь одно, а вспомнишь другое.
Немного не врубился в суть вопроса — наверное НГ делает свое дело. А что есть в этом контексте «несущая» частота? Частота, которая задает общую тональность голоса? Исключая обертоны, гармоники и прочее?
Мышонок
Друг Кота
Карма: 6 Рейтинг сообщений: 30 Зарегистрирован: Чт сен 14, 2006 11:42:09 Сообщений: 3792 Откуда: Обитаю на чердаке Рейтинг сообщения: 0
_________________ Память очень интересная штука: бывает так, что запомнишь одно, а вспомнишь другое.
_________________ путь наименьшего сопротивления проходит по пути наитолстого провода (с) Сергей Соболь
Мышонок
Друг Кота
Карма: 6 Рейтинг сообщений: 30 Зарегистрирован: Чт сен 14, 2006 11:42:09 Сообщений: 3792 Откуда: Обитаю на чердаке Рейтинг сообщения: 0
Т.е. как я понял, мы берем частоту какой-нибудь основной (достаточно большой амплитуды) гармоники в качестве несущей? Сумма-то различных частот (гармоник) остаётся. Я понимал (да и КТ315В, наверняка, тоже), что несущая — это частота передатчика, которая модулируется всем спектром сигнала. Фактически мы перемножаем несущую на сигнал.
И вообще, долой заумные мысли! Новый Год на носу! Ну, за науку!
_________________ Память очень интересная штука: бывает так, что запомнишь одно, а вспомнишь другое.
Сэр Мурр
Модератор
Карма: 46 Рейтинг сообщений: 232 Зарегистрирован: Чт окт 27, 2005 18:50:07 Сообщений: 11174 Откуда: из мест не столь отдалённых Рейтинг сообщения: 0 Медали: 2
А может поступить так: Создать так сказать массив из гласных. Попробуйте сказать «до» и «во» звук одинаковой тональности «ди» и «ви» тоже одинаковой но расположены на другой несущей то есть как я понимаю голос человека состоит из массива частот гласных, одной несущей согласных и шума образующего согласные путём сложения с несущей согласных.
для 1) fбуквы а fбуквы и fбуквы о fбуквы у и тд. Причём они обязательно должны быть взаимосвязанны по определённому закону. Зная например fa путём расчёта я могу узнать все остальные f
Вообще-то если вы не заметили, то все пародисты передают лишь манеру речи, а никак не сам голос. Но если уж интересует само изменение голоса то вот что скажу: скажите букву А. нет, не так. чуть попротяжнее, широко раскрыв рот. Отлично! а теперь скажите О так же протяжно. Молодцы! пронаблюдаем: голос не меняется. как мы тянули букву А, так она и осталась. все звуки образуются из-за препятствий воздуху на пути, т.е. зубы, язык, губы, например при букве О губы вытягиваются в трубочку. Если же раскрыть рот, то снова получим А. Попробуйте, произносите другие гласные, согласные и вы поймете, что голос никак не меняется от типа произносимого звука. А вот если вы проговорите что-нибудь шепотом, то ваш шепот будет неотличим от чьего-либо другого.
Таким образом, задача упростилась к минимуму — собираем простейший вокодер и модулируем голос (протяжное А) жертвы своей речью и получаем примерно то что хотели. Как вариант используем синтетический звук — в программе-говорилке подбираем необходимый тембр и скорость речи. Но это имxo уход от темы, т.к. задача стоит в изменении голоса в реальном времени. Существую программы — вокодеры, изменялки речи(Rave Karaoke например), обрабатывающие голос, правда, с небольшой задержкой.
Вот что я подумал — а если поставить делитель частоты на выходе? получим ту же скорость, но более низкий тон голоса? или как?
_________________ Увлекательный ресурс об электронике и не только